Data partitioning helps to speed up your Amazon Athena queries, and also reduces your cost, as you need to query less data.
Partitioning data means that we split the data up into related groups of data. Possible partitions could be date (time-based), zipcode, different types (contexts), etc. When querying the data, the query is constrained to a particular partition thus not querying the whole dataset. AWS Athena cost is based on the number of bytes scanned. Partitioning will have a big impact on the speed and cost of your queries.
To start using Amazon Athena, you need to define your table schemas in Amazon Glue. Amazon Glue is a managed ETL (extract, transform, and load) service that prepares and loads the data for analytics. To define the data schema you can either have a static schema or you can use a crawler. The crawler will scan the data and determine the schema of the data automatically. This will then be used to populate the AWS Glue Data Catalog with tables.
In our use case we had two problems to solve:
Incoming event data from firehose needs to be partitioned in S3 to achieve lower costs and faster queries in Athena; When we partition our data, we need to make Athena aware of this newer partitioning schema in an automated way Below we explain these 2 problems with solution in detail.
Data Partitioning
If ingestion happens through Amazon Kinesis Firehose, the data will be buffered and periodically written to S3. Then a lambda function can be used to read the S3 files (periodically or on write) and perform the partitioning. S3 objects are immutable, so new objects with the correct partitioning prefix will have to be created.
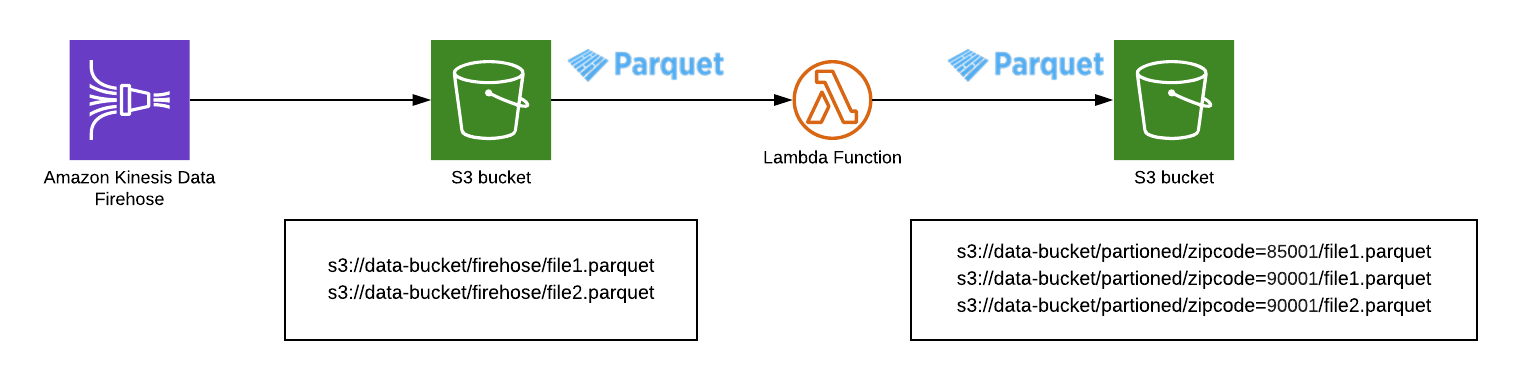
We used a lambda function written in Golang to do the repartitioning of the parquet data. We’re using our own MapReduce framework (https://github.com/in4it/gomap)[https://github.com/in4it/gomap]. The framework allows us to use the “reduce” functionality to group all the data with the same key, in our example, the zip code.
Updating Glue Partitions
There are different approaches to update your partition metadata. In Amazon Athena, you can:
Manually add each partition using an ALTER TABLE statement. Automatically add your partitions, you can achieve this by using the MSCK REPAIR TABLE statement. This invokes a scan operation which will scan your data to identify new partitions. In a lambda function, you can use AWS SDK to automate the creation of partitions. Rather than using Athena, you can directly make the changes in Glue. After all, Glue is used by Athena, so it’s best to change it in Glue directly.
The following snippet shows 4 Golang functions to achieve the glue partitioning schema updates:
- repartition: can be called with glue database name, table name, s3 path your data, and a list of new partitions. This function will compare the existing partitions with the new partitions and will create new partitions when necessary
- getAllPartitions: a function to get all glue partitions from table
- createPartition: create a new partition in glue
- compare: compare your new partitions with the current partitions
The last 3 functions are called by the repartition function.